
Amazon Aurora DSQL ha sido probablemente el anuncio más impactante en los últimos años en AWS, es un avance brutal que añade una nueva capa a un servicio como Amazon Aurora que ya era impresionante.
Eso sí, no es una BBDD para todos los públicos y vamos a hablar de ella en esta serie de artículos, en este primer artículo vamos a hablar de cómo hemos llegado hasta aquí y qué alternativas tenemos a Amazon Aurora DSQL, porque Amazon Aurora DSQL puede no ser lo más adecuado para nuestro caso de uso.
Por resumir que es Amazon Aurora DSQL, es una BBDD distribuida que permite la consistencia en escritura y por tanto permite transacciones ACID en multi-región.
En este artículo vamos a ver:
- Que es ACID y su importancia
- Cómo han ido evolucionando las BBDD para ser más eficientes.
- Cómo Aurora revolucionó las BBDD.
- Que nos aporta Aurora Global Database y qué limitaciones tiene.
- Por qué necesitamos Aurora DSQL
¿ACID qué es eso?
Lo primero es aclarar que es ACID (Atomicity, Consistency, Isolation and Durability).
ACID es un término que se acuñó en 1983 y en el que se basa todo el desarrollo de las BBDD actuales y aunque se acuñó en 1983, desde 1973 ya existían este tipos de Bases de Datos.
Para ser ACID compliant una BBDD debe permitir que sus transacciones cumplan estos requisitos:
Atomicity (Atomicidad)
Una transacción suele tener múltiples pasos, pero tiene que tratarse como una única entidad o la transacción se ejecuta correctamente o falla en su totalidad, no puede dejar datos modificados parcialmente.
Consistency (Consistencia)
La consistencia de una transacción es que los datos son consistentes, de forma que no puedan corromperse al ejecutar una transacción.
Isolation
El aislamiento garantiza que las operaciones se ejecutan de forma aislada y sin afectarse entre sí, de forma que al existir múltiples operaciones modificando el mismo registro una no se ejecute hasta que termine la anterior.
Durability
Garantiza que una transacción una vez completada no pueda perderse incluso en caso de desastre y que los datos sigan estando disponibles una vez recuperado el desastre.
¿Todas las BBDD soportan transacciones ACID?
No todas las BBDD soportan ACID, por ejemplo Amazon MemoryDB no es ACID e incluso otras BBDD en AWS como Athena o DynamoDB originalmente no soportaban transacciones ACID (Actualmente las 2 las soportan).
Ahora vamos a ver cómo se ha ido solucionando este problema históricamente y cómo hemos llegado a Amazon Aurora DSQL.
¿Es fácil conseguir que nuestra BBDD sea ACID?
No, no lo es, de hecho es una de las principales limitaciones de una BBDD, si alguna vez os habéis preguntado por qué las BBDD tienen tantos problemas con los sistemas de ficheros en Unix en general, es por esto.
Una transacción en BBDD suele conllevar muchas operaciones de lectura/escritura, además requiere cierto nivel de bloqueo (Mientras se realiza una transacción no se puede ejecutar otra que modifique los mismos datos).
Esto genera muchos problemas a nivel de latencia, pero no solo de latencia de red, incluso de latencia entre los propios componentes de un servidor. Para las BBDD históricamente la latencia de escritura a disco era un problema muy grande.
Los discos han mejorado mucho en velocidad, pero aun así no era suficiente, por eso hace unos años se optó por escribir en memoria en vez de disco. La memoria RAM es mucho más rápida en escritura y lectura por lo que todo son ventajas, pero también tiene una serie de problemas. Por un lado es volátil, con lo que podemos perder los datos y por otro lado tampoco podemos cargar el contenido entero, porque la memoria habitualmente tiene menos tamaño que nuestros discos.
Así que se optó por utilizar algo bastante habitual que es la memoria paginada que es crear “Páginas” de memoria que no dejan de ser bloques físicos de memoria. De esta forma podemos tener parte de nuestros datos en una página de memoria (Los datos frecuentes o nuevos) y volcamos de forma asíncrona los datos a disco para persistirlos. Esto además mejora tanto el performance al usar memoria, como el performance de disco ya que podemos optimizar las escrituras y las lecturas.
Pero tendríamos un problema en caso de un fallo antes de volcar los datos a disco o si necesitamos recuperarlos, pero esto se soluciona con un sistema de logging transaccional conocido como Write-Ahead Logging (WAL) que sigue el principio DO-UNDO-REDO.
Adicionalmente a escribir en memoria el resultado la transacción, se escribe un log con la transacción en sí:
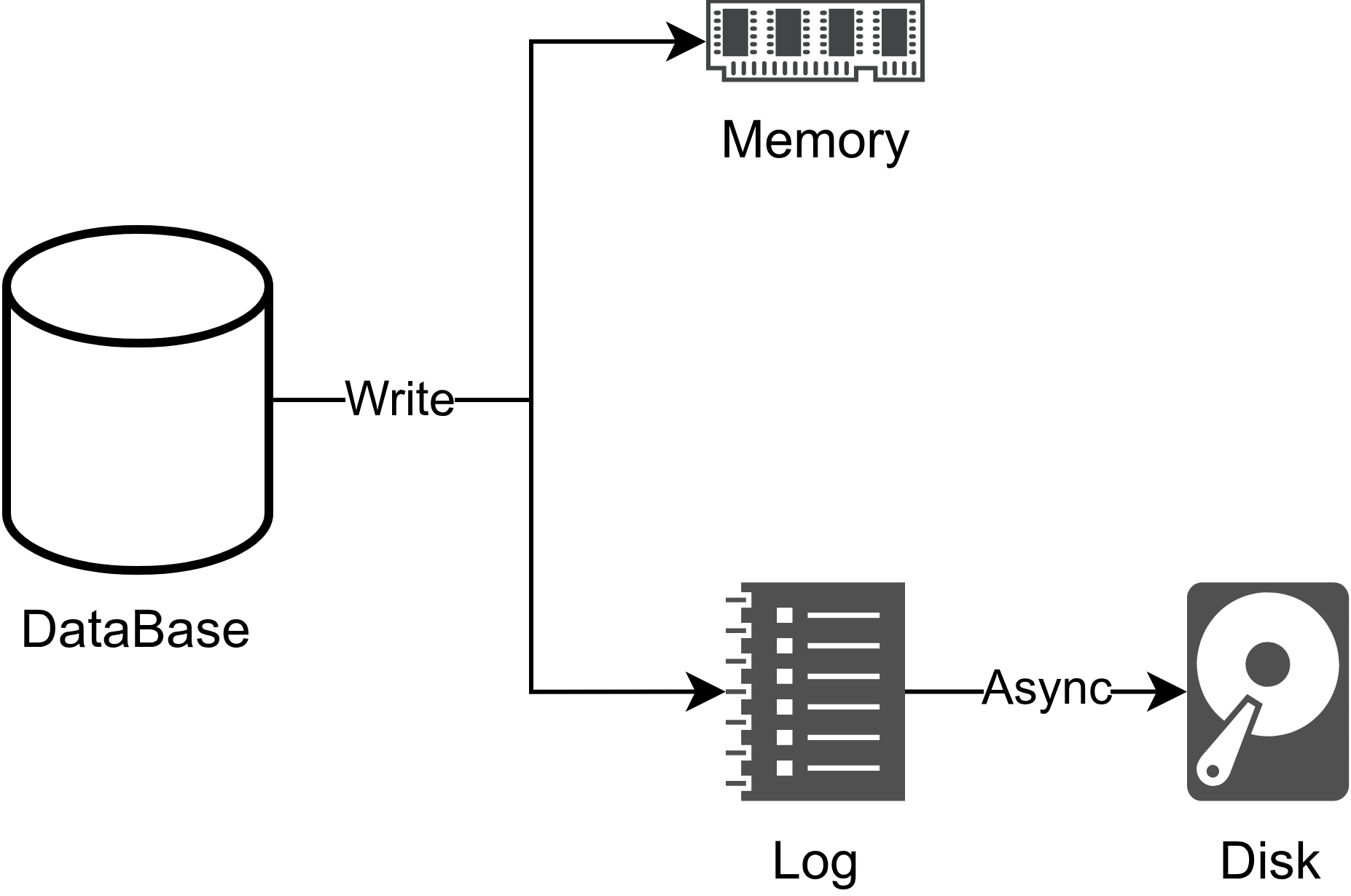 De esta forma si tenemos un fallo podemos cargar una página antigua que esté persistida y aplicar todos las transacciones que no se han persistido (REDO). O en caso contrario si queremos rectificar una transacción podemos saber que ha modificado y volver al estado anterior (UNDO):
De esta forma si tenemos un fallo podemos cargar una página antigua que esté persistida y aplicar todos las transacciones que no se han persistido (REDO). O en caso contrario si queremos rectificar una transacción podemos saber que ha modificado y volver al estado anterior (UNDO):
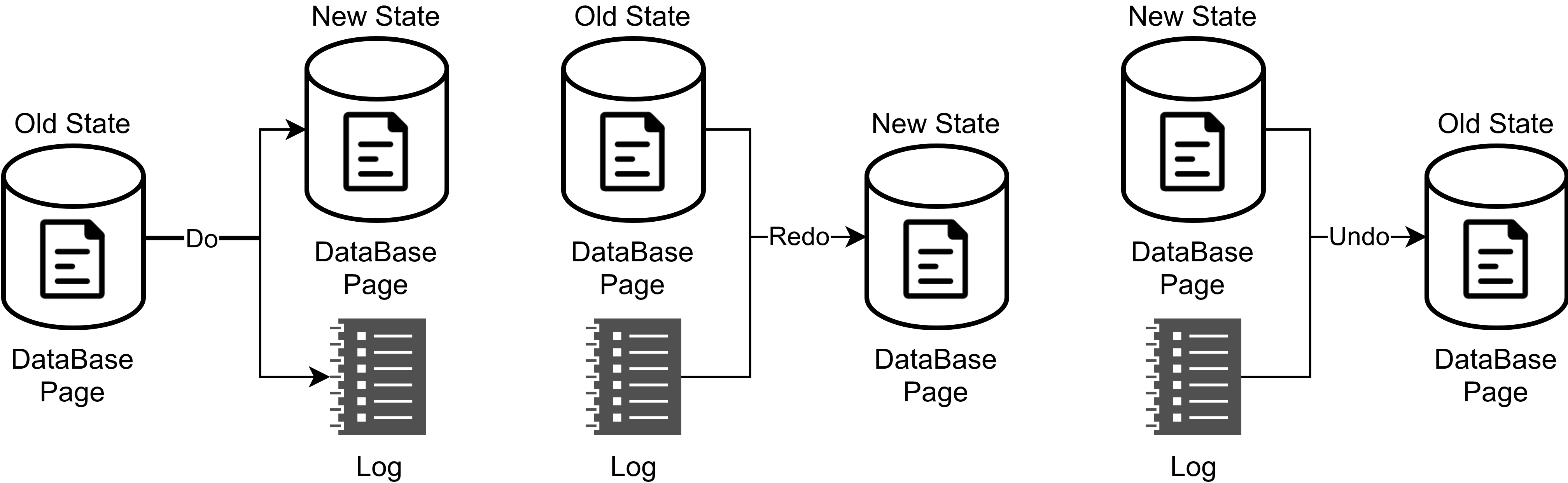
Este sistema mejora infinitamente el rendimiento de las BBDD y es algo que lleva utilizándose muchos años en cualquier motor de BBDD.
¿Y cómo una BBDD puede ser ACID en múltiples Zonas de Disponibilidad?
Hasta aquí hemos visto cómo conseguimos esto en un solo servidor, pero si queremos tener alta disponibilidad, tenemos que montar 2 servidores (Un primario y un Stand-By) y aquí aparece el principal problema de todos la latencia de red.
Una transacción no es solo una lectura o escritura en una BBDD, sino que es una secuencia de operaciones y por tanto el tiempo de ejecución de una transacción depende de la latencia.
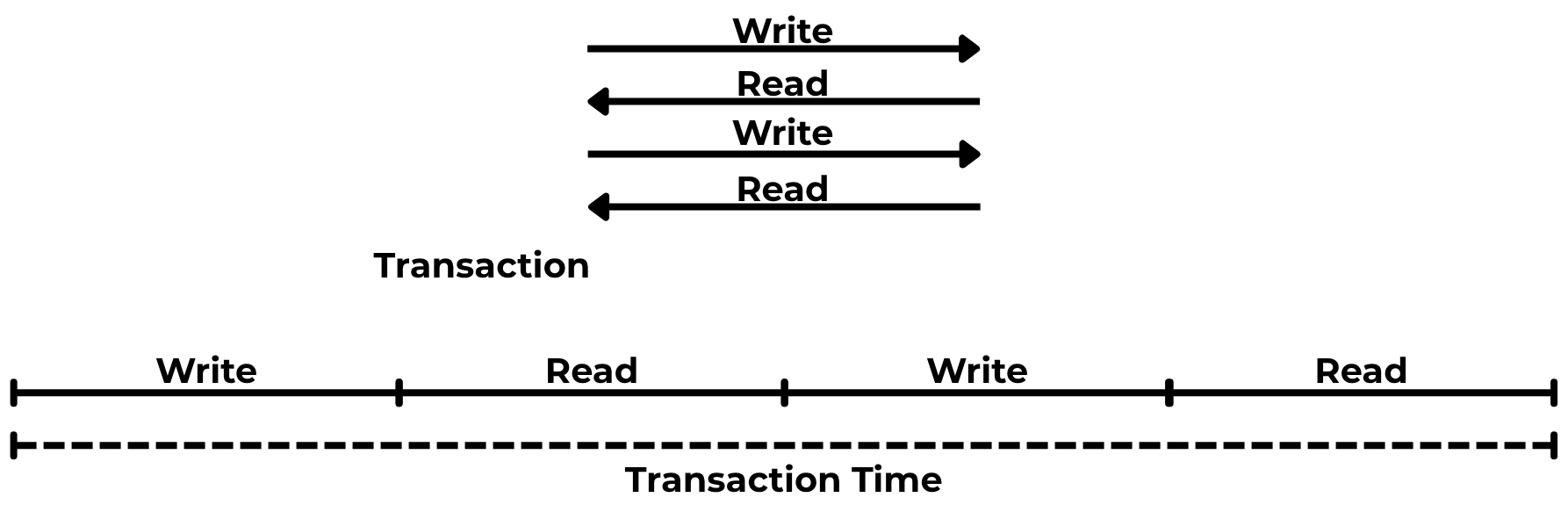 Esto es un problema con una replicación síncrona, porque tenemos que esperar a que cada operación se replique. Esto incrementa mucho la duración de la transacción, porque tenemos que mandar la operación por red, que se ejecute en la réplica y esperar a que nos devuelva el ACK. Como la latencia de red es mucho más elevada, el tiempo de ejecución de una transacción se multiplica exponencialmente.
Esto es un problema con una replicación síncrona, porque tenemos que esperar a que cada operación se replique. Esto incrementa mucho la duración de la transacción, porque tenemos que mandar la operación por red, que se ejecute en la réplica y esperar a que nos devuelva el ACK. Como la latencia de red es mucho más elevada, el tiempo de ejecución de una transacción se multiplica exponencialmente.
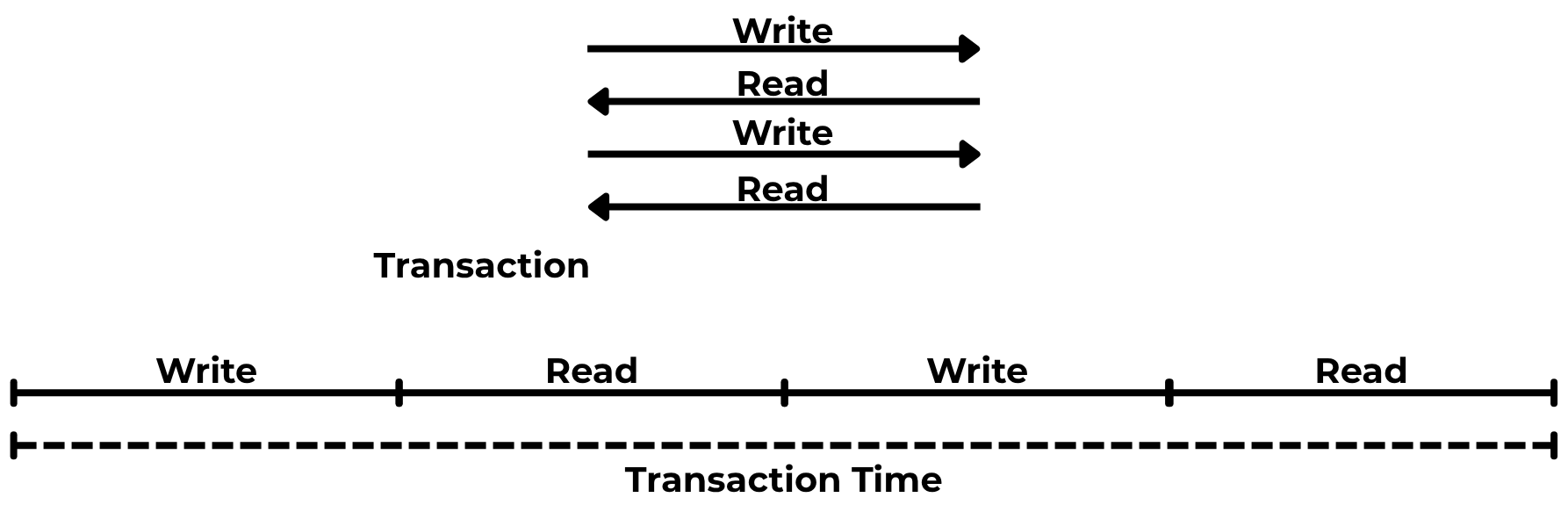 Podemos optar por una solución un poco más eficiente, que son las Read Réplicas, que en vez de utilizar una replicación síncrona utilizan una replicación asíncrona, de forma similar a como hacíamos con el disco, pero que van a tener un lag de replicación que es el tiempo en el que la réplica no tendrá el dato actualizado.
Podemos optar por una solución un poco más eficiente, que son las Read Réplicas, que en vez de utilizar una replicación síncrona utilizan una replicación asíncrona, de forma similar a como hacíamos con el disco, pero que van a tener un lag de replicación que es el tiempo en el que la réplica no tendrá el dato actualizado.
Seguramente os preguntaréis cómo podemos garantizar que una transacción es ACID con una replicación, si vamos a tener un lag de replicación, la respuesta es sencilla, limitando las escrituras a una sola instancia. De esta forma garantizamos la consistencia y el aislamiento.
¿Es mejorable?
Este método era mejorable, ya que el lag de replicación nos puede afectar bastante y aquí es donde entra la magia de Amazon Aurora.
Amazon Aurora hizo algo muy interesante que fue separar la capa de Almacenamiento y la de Computo. Dejando el motor de la BBDD en una instancia y gestionando la capa de almacenamiento de forma independiente.
El motor de BBDD es exactamente igual, pero a la hora de realizar una escritura en vez de llamar directamente a disco, llama a los Storage Node de Aurora.
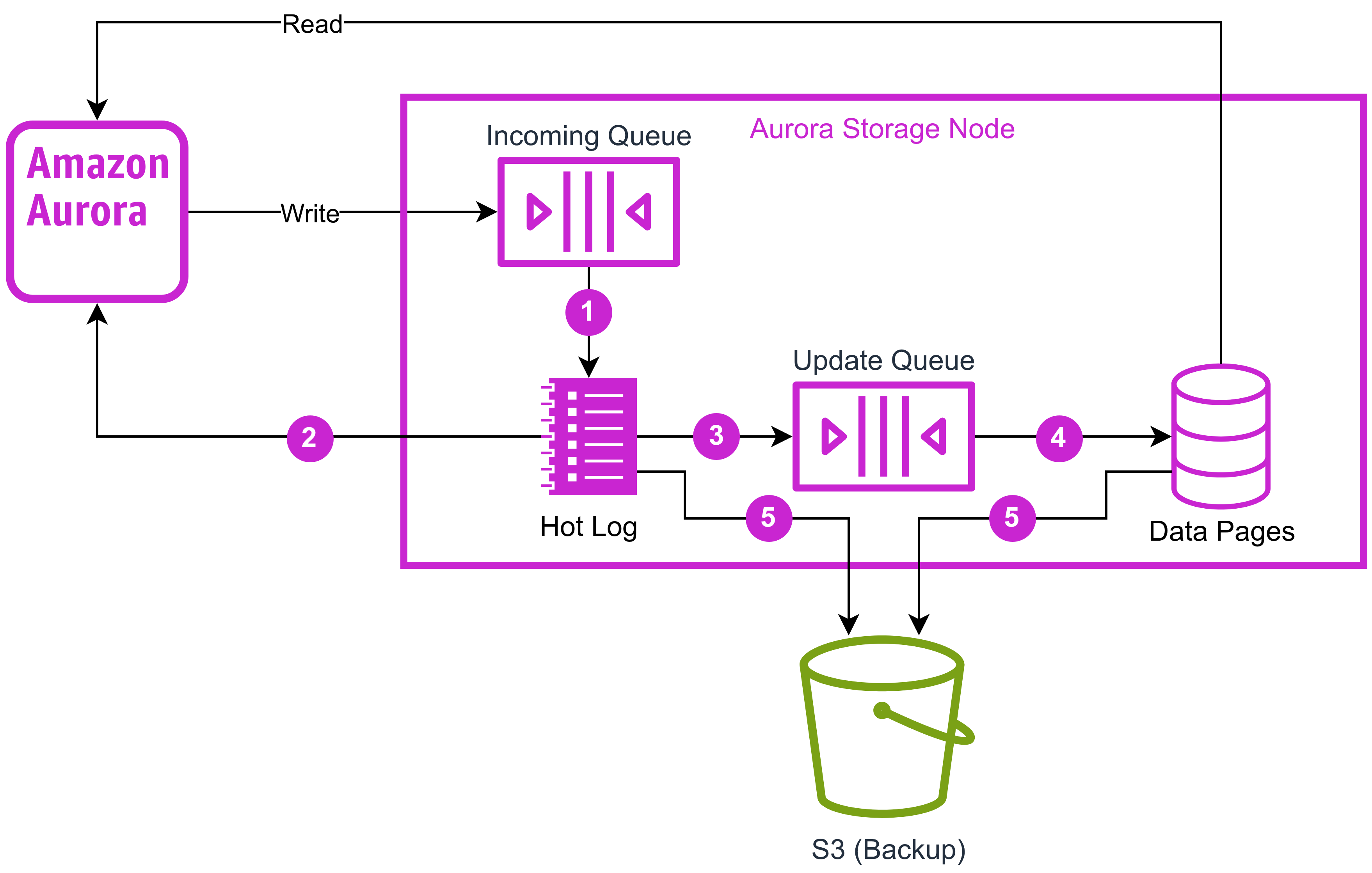 Cada nueva escritura lanza este esquema:
Cada nueva escritura lanza este esquema:
- Los registros se reciben en el Incoming Queue y se almacenan en el Hot Log en memoria
- Se devuelve el ACK al motor de la BBDD sin esperar la persistencia
- Los datos se registran en el Update Queue y se agrupan para optimizar las escrituras
- Se genera un nuevo Data Page distribuyéndolo en 6 copias sincronizadas (2 por cada AZ)
- Se realizan backups periódicos de Hot Logs y Data Pages a S3
De esta forma se consigue una latencia de replicación muy baja, menor a 100 ms (La cual es bajísima para un entorno multi AZ) en varias zonas de disponibilidad repartidas en 6 Copias, además se consiguen backups continuos y la posibilidad de hacer restauraciones a puntos determinados de tiempo.
Lo mejor es que esto no impacta en el rendimiento de la BBDD ya que las operaciones de Storage no se ejecutan en la misma instancia donde está nuestro motor de BBDD, permitiendo un mayor rendimiento en general.
Y además se replica vía Log todas las transacciones en todos los nodos.
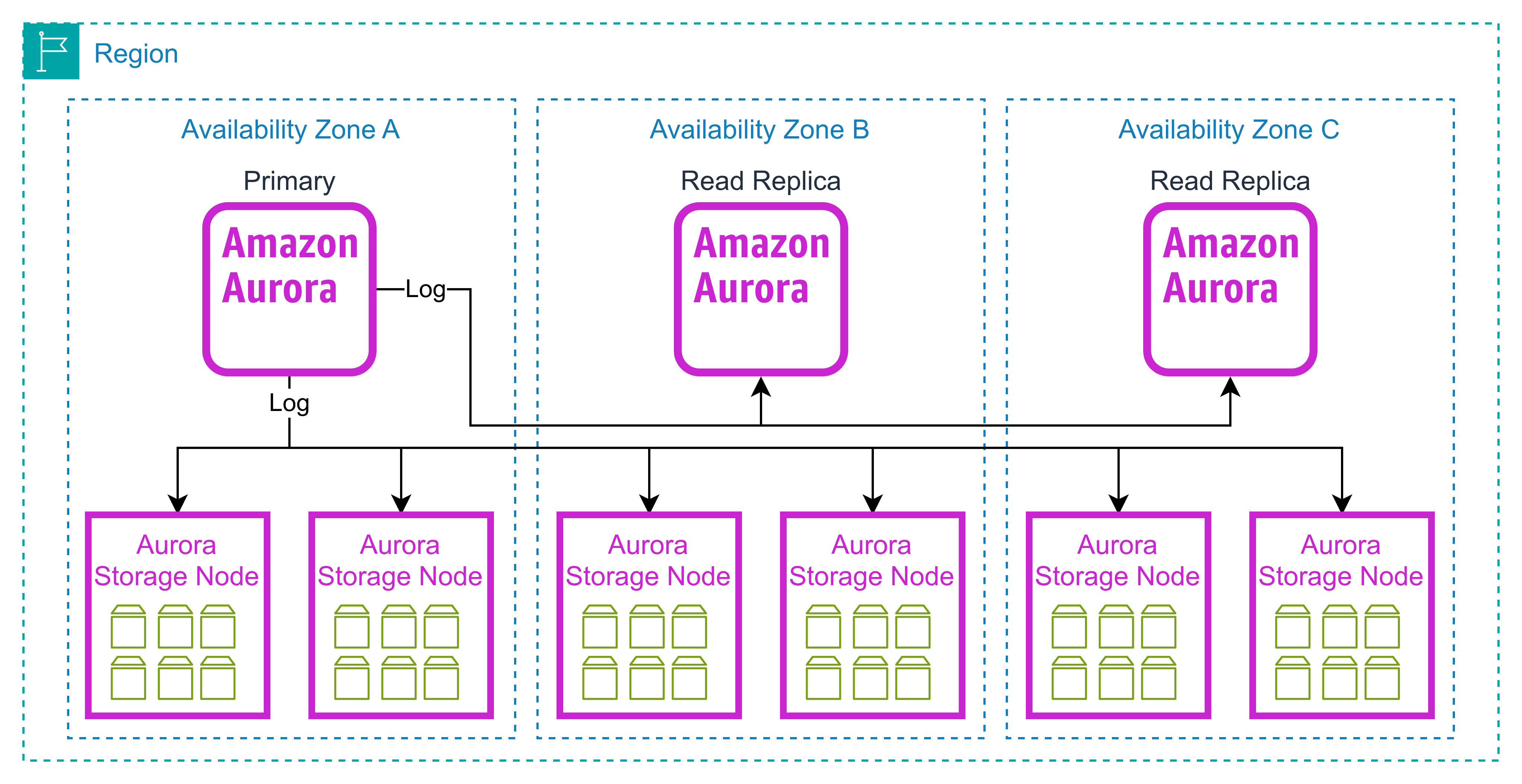 Aurora soporta hasta 15 read réplicas y 64 TB de almacenamiento automático y puede manejar hasta 500,000 lecturas y 100,000 escrituras por segundo.
Aurora soporta hasta 15 read réplicas y 64 TB de almacenamiento automático y puede manejar hasta 500,000 lecturas y 100,000 escrituras por segundo.
Nota: Existen más pasos que he simplificado para un correcto entendimiento, ya que es un almacenamiento distribuido, no solo existe un nodo de Storage, etc.
Nota 2: A nivel de motor de BBDD también se guardan los registros en memoria de forma que la escritura es más rápida.
¿Y en múltiples Regiones?
Si necesitamos replicar nuestra BBDD en otra región, nos vamos a encontrar que la latencia de replicación es mucho mayor, básicamente porque la latencia de red entre regiones es muy alta.
Pero aquí es donde entra Amazon Aurora Global Database a ayudarnos.
Amazon Aurora Global Database extiende su modelo de replicación a otras regiones, en este caso además de separar la capa de Almacenamiento, separa la capa de replicación.
De esta forma vamos a tener una capa independiente para gestionar la replicación entre regiones y una capa de storage independiente para gestionar la replicación entre zonas. Esto permite que Amazon Aurora Global Database tenga mejor rendimiento a nivel de BBDD y una replicación entre regiones muy optimizada.
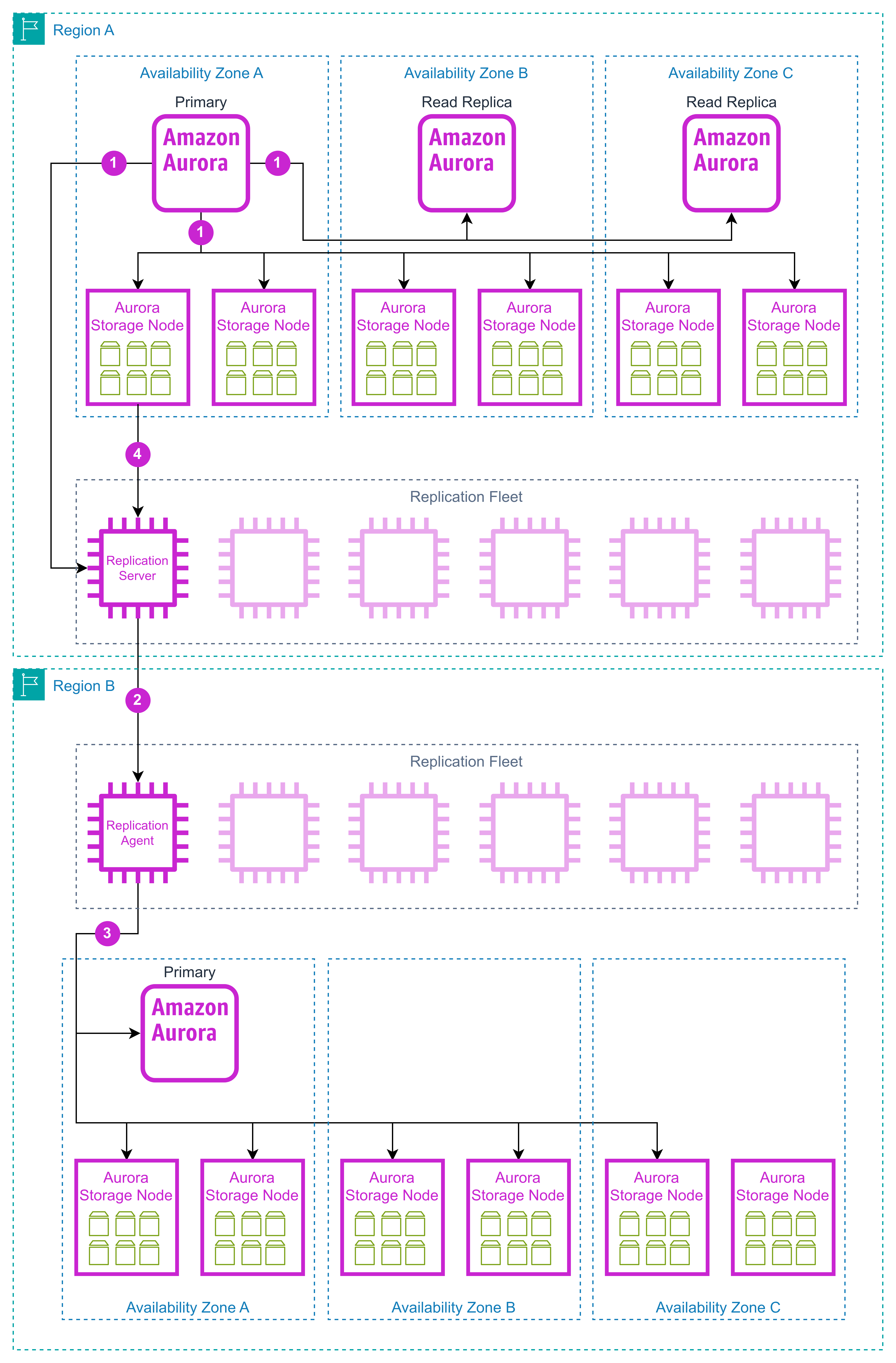 Cada nueva escritura lanza este esquema:
Cada nueva escritura lanza este esquema:
- Se escriben los nuevos registros en los Storage nodes y réplicas de la BBDD zonales y adicionalmente se escribe en un servidor de replicación.
- El servidor de replicación replica los registros de escritura en el servidor con el agente de replicación perteneciente al grupo de servidores de replicación en otras regiones.
- Este servidor de replicación actúa como si fuese una BBDD primaria y ejecuta los registros de escritura tanto en la réplica global de la BBDD como en los Storage nodes de esta región.
- Por último, si el servidor de replicación detecta que no ha recibido algún registro de escritura, los recogerá de los storage nodes de la región primaria.
De esta forma también se consigue una latencia de replicación muy baja, menor a 1 segundo en hasta 5 regiones secundarias. Cada región secundario tendrá adicionalmente replicación en zonas de disponibilidad y 6 Copias repartidas entre ellas, además tenemos backup multiregionales y continuos ya que el backup se almacenará también en cada región secundaria.
¿Y la escritura en múltiples regiones?
Es el mayor problema que hay en este modelo, ya que las escrituras solo pueden ejecutarse en la región primaria y por tanto la latencia de escritura en multiregión es altísima.
Existe una solución intermedia que es utilizar write forwarding en Amazon Aurora, esto nos permite configurar una réplica global para escribir en ella, aunque realmente lo que estamos haciendo es enviar estas peticiones con un forward a la BBDD principal. Es una forma un poco más eficiente de escribir en multiregion, que nos permite utilizar endpoints por región, pero no es muy eficiente en escritura.
El Desafío de las escrituras multiregión consistentes
Como hemos visto, tanto Amazon Aurora como Aurora Global Database han resuelto los problemas de rendimiento y replicación, siguen teniendo una limitación fundamental: las escrituras deben centralizarse en una región primaria para garantizar la consistencia ACID.
Esta arquitectura funciona perfectamente para aplicaciones que pueden funcionar con escrituras centralizadas, pero ¿qué pasa cuando necesitamos que usuarios en diferentes regiones puedan escribir con baja latencia manteniendo la consistencia de escritura? Aquí es donde Amazon Aurora DSQL entra a escena.
Uno de los problemas de las escrituras, es controlar la secuencia de tiempos, porque si lanzamos una escritura desde una región y lanzamos otra escritura sobre el mismo registro 100ms después en otra región, para cada una de estas regiones el dato correcto no es el mismo, porque no podemos controlar el tiempo y tendremos un problema de consistencia bastante grande. (Bueno realmente sí podemos controlar el tiempo, pero lo veremos en el próximo artículo).
Conclusiones.
A lo largo de este artículo hemos recorrido la evolución en AWS que ha llevado al desarrollo de Amazon Aurora DSQL, desde los fundamentos de ACID hasta las limitaciones de los sistemas multiregión actuales.
El sistema de replicación que utiliza Amazon Aurora y Amazon Aurora Global Database es una auténtica maravilla, porque mejora el performance increíblemente y además reduce los tiempos de replicación drásticamente.
Si no necesitamos escrituras multiregion Amazon Aurora o Amazon Global Database es la mejor opción para la mayoría de casos, pero en caso de requerir una BBDD global, distribuida y con escritura consistente en multiregion tenemos que optar por Amazon Aurora DSQL.
| Característica | Aurora | Aurora Global | Aurora DSQL |
|---|---|---|---|
| Latencia escritura | Baja en la zona primaria | Baja en la zona primaria y alta en multiregion | Baja en multiregion |
| Regiones escritura | 1 | 1 primaria y hasta 5 adicionales con write forwarding | Múltiples |
| Read réplicas | Hasta 15 | Hasta 16 por región | Distribuidas globalmente |
| Casos de uso | Apps regionales | Apps globales con lectura intensiva, dashboards | Apps globales con escritura intensiva en múltiples regiones, gaming, IoT |
¿Cuánto cuesta Aurora DSQL?
Aunque AWS todavía no ha publicado precios oficiales, Aurora DSQL será considerablemente más caro que Aurora debido a su complejidad distribuida.
Tomando como referencia Aurora MySQL/PostgreSQL
Aurora Global Database: es un 65% más caro
Aurora DSQL: Se estima entre 3 y 5 veces más que Aurora Global
¿Cuál elegir?
NO uses Aurora DSQL si:
- Tus escrituras pueden centralizarse en una región (>80% de casos)
- Necesitas usar MySQL como motor de BBDD
- Tus transacciones no requieren baja latencia en escritura multiregión
Puedes utilizar Aurora Global Database cuando :
- Puedes tolerar write forwarding o escrituras en una sola región
- Requieres lecturas intensivas multiregion con escrituras ocasionales
- Necesitas un DR multiregión pero no escrituras activo-activo
Puedes utilizar Aurora Cuando:
- Tienes Aplicaciones regionales
- El presupuesto limitado
- Requieres una simplicidad operacional
Ahora que tenemos claro el problema, nos tenemos que hacer una pregunta: ¿Cómo ha conseguido AWS una BBDD con escritura multiregional sin romper ACID?
En el próximo artículo desvelaremos los secretos de Aurora DSQL y como AWS ha conseguido domar el tiempo en una BBDD.
👉 Próximo: “Aurora DSQL: Como controlar el tiempo”